At Greendeck.co, we leverage deep learning to drive operational efficiency and innovation in online retail. We empower our clients with smart engines that are capable of tasks like tracking competitor’s products, pricing & promotions in real time and categorizing products automatically on the basis of descriptive text & images. This allows business folks to focus on what they do best- make decisions that drive growth.
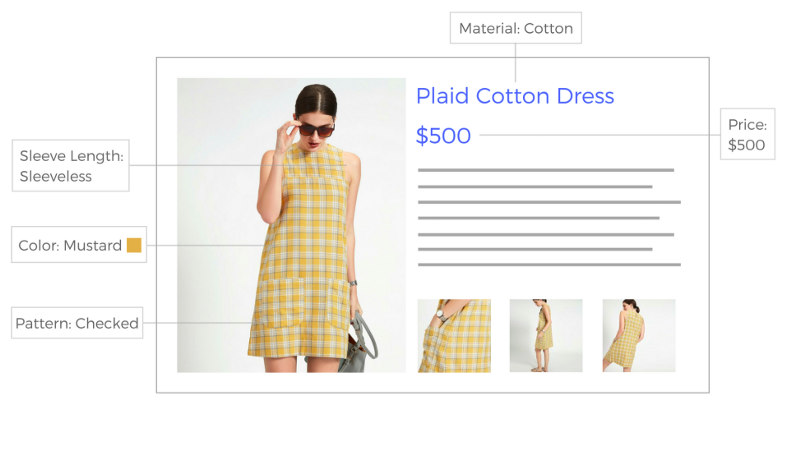
In this blog, we talk about a Keras data generator that we built (on top of the one described in this kickass blog by Appnexus) that takes in a pandas dataframe and generates multiple batches of outputs, each batch for a different classification task (works for multi label as well as multi class classification).
P.S.- If you were drawn to this blog post for building your own CSV data generator with different specification than ours, stay put and follow the same instructions. Just change the ‘X’ and ‘Y’ variables in greendeck_akmtdfgen.pyto suit your own use case (along with of course, the training file) and you’ll be good to go!
Context
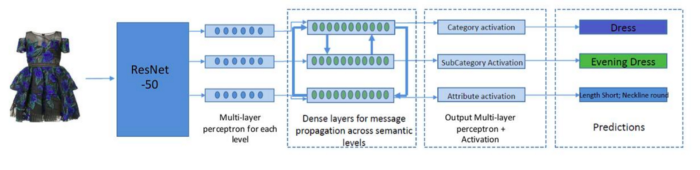
While building classifiers for fashion products, we realised that there’s a considerable interdependence between product categories and attributes. To leverage this correlation, we decided to use a branched multi output model for predicting the category (ex. jeans) as well as the attributes (ex. colour, jean type, bottomwear fit). We wanted to leverage the interdependence both ways, that is, how attribute is affected by category and vice versa, so we came up with a branched multi output model inspired by this paper.
Issue with built in Keras data generator
Even though Keras Image generator is super convenient with image augmentation et al. in place, it generates batches in two ways — .flow and .flow_from_directory. The issue with .flow_from_directory is that images need to be rearranged into different folders and since we were working with millions of images on multiple classification tasks, this seemed to be suboptimal. We simply wanted to feed in a csv file with locations of images on the machine and corresponding labels and generate training data.
Well, we could have created vectors for the targets and used .flow, but then that would mean feeding all the images in a single numpy array. As we know, there are only so many images that can be loaded into an array given the RAM constraints, so that isn’t feasible as well.
Custom data generator described in Appnexus blog takes a pandas dataframe and generates batches. This solves a part of the problem by not requiring to rearrange files in folders and load all images in one single array.
However, like .flow and .flow_from_directory, the custom generator outputs only one output array (say y_output) while we need something like~
y_output = {'output1': y1, 'output2': y2} #https://stackoverflow.com/questions/38972380/keras-how-to-use-fit-generator-with-multiple-outputs-of-different-type
to train the multi-output model.
So we made some changes to the script given by Appnexus to suit our use case. If you are in need of a data generator for a multi- output model, you may follow these steps:
- Download greendeck_akmtdfgen.py and place it in the same folder as your training file
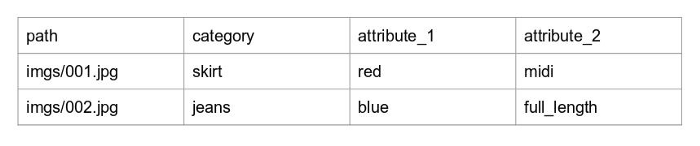
- Arrange your csv file such that is has headings for each column. Also, the first column must be the path of the corresponding image.
- Add this code snippet to the top of your training file
- Give names to your prediction layers in the model and call required functions to get the number of outputs. If it is a multi class classification task, use get_num_classes_column_lb(), if it is a multi label classification task, use get_num_classes_column_mlb(). The first parameter of these functions is the column heading (in CSV) in case of multi- class classification and an array of column headings (in CSV) in case of multi- label classification. Rest two parameters needn’t be bothered about.
--> output1 = Dense(get_num_classes_column_lb("category", df_overall, headings_dict), activation='linear', name='output1')(x)--> output2 = Dense(get_num_classes_column_mlb(["attribute-1","attribute-2"], df_overall, headings_dict), activation='linear', name='output2')(x) - Modify the following variables to suit your need:
→ file_name : name of the csv which has image paths and corresponding labels
→ df_train = training data frame
→ df_validation = validation data frame
→ df_overall = concatenation of df_train and df_validation ideally (purpose is to have the union of labels in df_train and df_validation in one dataframe)
→ parametrization_dict = dictionary specifying which all headings are to be considered for what kind of trainingEx- parametrization_dict = {‘multi_class’:[{‘output_1’:’category'}, {‘output’:’sub- category'}], ‘multi_label’:[{‘attribute_output’:[‘bottomwear_fit’,’jean_type’,’dress_type’,’skirt_type’,’neckline’,’sleeve_length’]}]}
The dictionary has two keys — multi_class and multi_label.multi_class is an array of dictionaries, each dictionary being a key- value pair where key is the output name defined in the model and value is the corresponding name in the csv headings.multi_label is an array of dictionaries. Key of each dictionary is the output name defined in the model and value is an array of headings that need to be clubbed under one multi-label classification task (the current example takes all the six attribute classes, combines them and then does multi label classification on the whole pool of attributes ==> size of prediction vector = (batch_size, total unique values in the six columns put together)). - Compile and fit the model
target_size = (224, 224) # size of input image
model.compile(optimizer='rmsprop', metrics=['accuracy'], loss={'category_output': 'categorical_crossentropy', 'sub_category_output' : 'categorical_crossentropy', 'attribute_output' : 'binary_crossentropy'})
train_generator = generator_from_df(df_train, df_overall, headings_dict, batch_size, target_size, features=None, parametrization_dict = parametrization_dict)
validation_generator = generator_from_df(df_validation, df_overall, headings_dict, batch_size, target_size, features=None, parametrization_dict= parametrization_dict)
nbatches_train, mod = divmod(ntrain, batch_size)
nbatches_valid, mod = divmod(nvalid, batch_size)nworkers = 10model.fit_generator(
train_generator,
steps_per_epoch=nbatches_train,
epochs=epochs,
verbose=2,
validation_data=validation_generator,
validation_steps=nbatches_valid,
workers=nworkers)
Appendix:
- We are carrying out image augmentation on the fly using imagaug. You can change the specifications by altering code in lines # 22 to 30 in greendeck_akmtdfgen.py and disable it altogether by commenting out line #231 to 236.
- Even though it’s meant for images, you can change lines # 208 to 232 in greendeck_akmtdfgen.py to modify the input.
- When you run your training code, some files of the format <output-name>_classes.txt would be generated. These files contain labels corresponding in the order of class indices for the classification task. For instance, if categories_classes.txt contains “dresses,skirts,tops” then classification task having output layer name “categories” is predicting on three classes, with the zeroth index prediction indicating dresses, first index prediction indicating skirts and second index indication tops.