At Greendeck, in addition to pricing, we also provide market intelligence to our customers, and to do that we capture thousands of snapshots of various websites and newsletters daily.
How are market intelligence and capturing snapshots related?
There are so many variables involved that need to be tracked by an eCommerce company to set the pricing of their products, offers, and sales they need to run. They need to track the pricing of their competitor’s products, the performance of their promotions, email newsletters, and products they’re featuring on their front page of websites.
Capturing snapshots of the front page of every competitor’s website and the newsletters they’re sending helps achieve this.
How is this helpful?
This is specifically very helpful for marketers. As marketers try to understand which particular brands run a sale on a particular day, and also plan the promotion of their own products through their newsletter.
In the previous blog post, I discussed the core of the data side of the retail intelligence part of Greendeck.
In this one, I will touch upon the data side of tracking some of the marketing moves that an eCommerce store makes. These mainly include; tracking their websites, the products they’re featuring, the promotions they’re running, and the newsletters they’re sending to their customers.
Building this service is like building our own little web archive machine. It was a lot of fun and we will be sharing with you how we’re doing what we’re doing.
Mainly, two services do all of this job. One is Snapshot service and the other one is Newsletter service.
Snapshot service
To put simply, given a website URL or HTML, this service captures the snapshot of the full page and stores it on an Amazon S3 bucket. It runs 24x7 and all of this is done automatically. It handles all of the problems of popups that appear and does all of the tasks using a headless browser. We will get to know how it does all of these things in this post.
Newsletter service
This service tracks all of the newsletters sent by the eCommerce stores to their customers. There are many moving parts in this service but I'll talk about them some other day!
Note: This service makes heavy use of snapshot service to render the HTML on a headless browser and then capturing the snapshot.
Snapshot service
Snapshot service is a light-weight flask app that runs for 24x7 with mainly two end-points: /url and /html endpoint.
The /url endpoint accepts a URL in the post request along with many parameters like the time for which the driver has to wait for the page to be rendered.
First, we tried out just opening the given URL in a headless browser without doing much and then capturing the snapshot of the page. But it didn’t go as per expectations. Here, are some of the problems that we encountered and how we solved them:
a) Some of the websites didn’t open at all. Why? Websites were blocking us because they know it’s code that is requesting the resource and not the human. So, we used user agent to solve this problem.
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
user_agent = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
chrome_options.add_argument('user-agent={0}'.format(user_agent))b) After using the user agent, we encountered another problem and that is the resultant page isn’t getting rendered in the way we want. Why? Single page apps. This revolution of building single-page apps using frameworks like Vue and React is very common in the web development industry. The driver needs some time to assemble all of that heavy javascript that server returns to render it as a full page.
Solution: Wait for some seconds to get the page rendered in the browser.
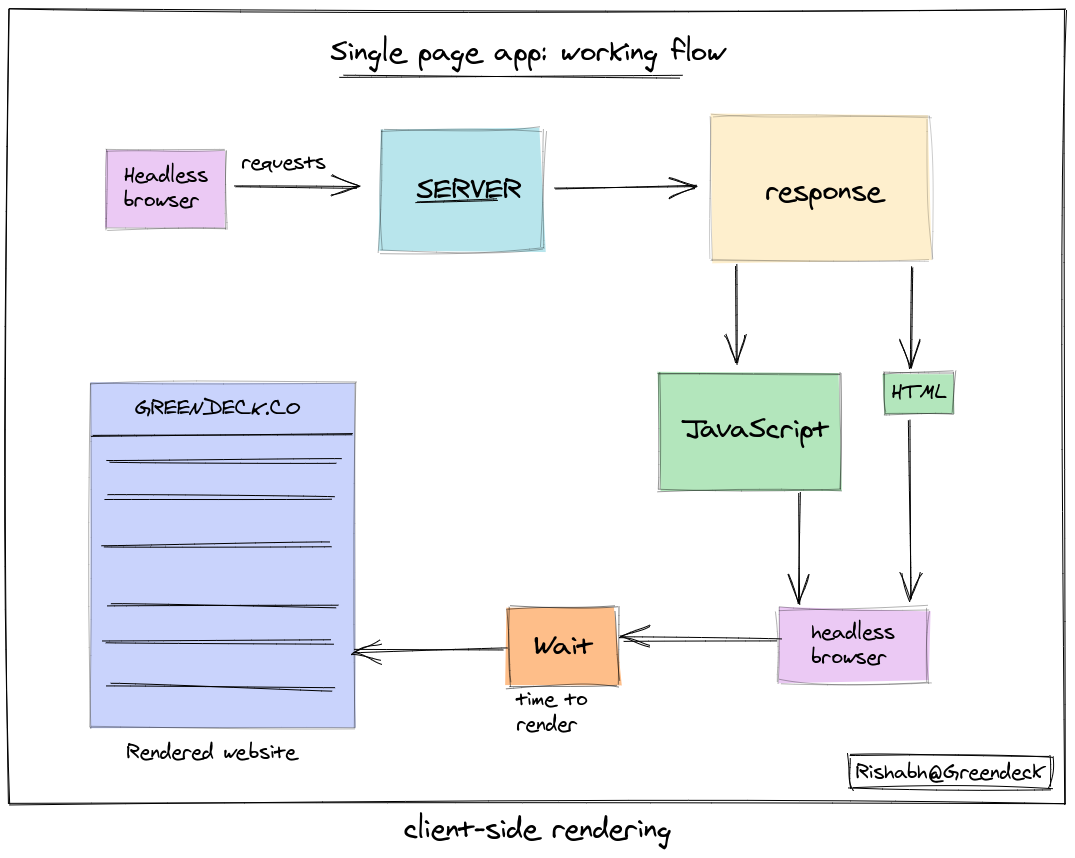
c) Blocking or removing the popups:
Nearly every website that we visit flashes out some popups as soon as you visit them. It can be an offer that’s running on, or just an embedded page to subscribe to their newsletter. We also need to remove them before capturing the screenshot.
Solution: Pass the required parameters along with website URL in a post request related to popups like the Xpath of popup and class name of popup so that the popup element can be captured by chrome driver and then we can use click function to remove it.
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
element_present = EC.presence_of_element_located((By.XPATH, popup_xpath))
WebDriverWait(driver, time_delay).until(element_present)
driver.find_element_by_xpath(popup_xpath).click()d) Capture the full height and width of the page:
We need to capture the full page of the website in one single snapshot. To do so, we need to calculate the total height and width of the page by scrolling it down from the top (0,0) to bottom so that we can further set the height and width of the chrome driver.
def get_height_and_width(driver):
'''
Fetch the height and width of the full page
'''
total_width = driver.execute_script("return document.body.offsetWidth")
total_height = driver.execute_script("return document.body.parentNode.scrollHeight")
viewport_width = driver.execute_script("return document.body.clientWidth")
viewport_height = driver.execute_script("return window.innerHeight")
rectangles = []
i = 0
while i < total_height:
ii = 0
top_height = i + viewport_height
if top_height > total_height:
top_height = total_height
while ii < total_width:
top_width = ii + viewport_width
if top_width > total_width:
top_width = total_width
rectangles.append((ii, i, top_width,top_height))
ii = ii + viewport_width
i = i + viewport_height
previous = None
part = 0
for rectangle in rectangles:
if not previous is None:
driver.execute_script("window.scrollTo({0}, {1})".format(rectangle[0], rectangle[1]))
# time.sleep(0.5)
time.sleep(0.1)
if rectangle[1] + viewport_height > total_height:
offset = (rectangle[0], total_height - viewport_height)
else:
offset = (rectangle[0], rectangle[1])
previous = rectangle
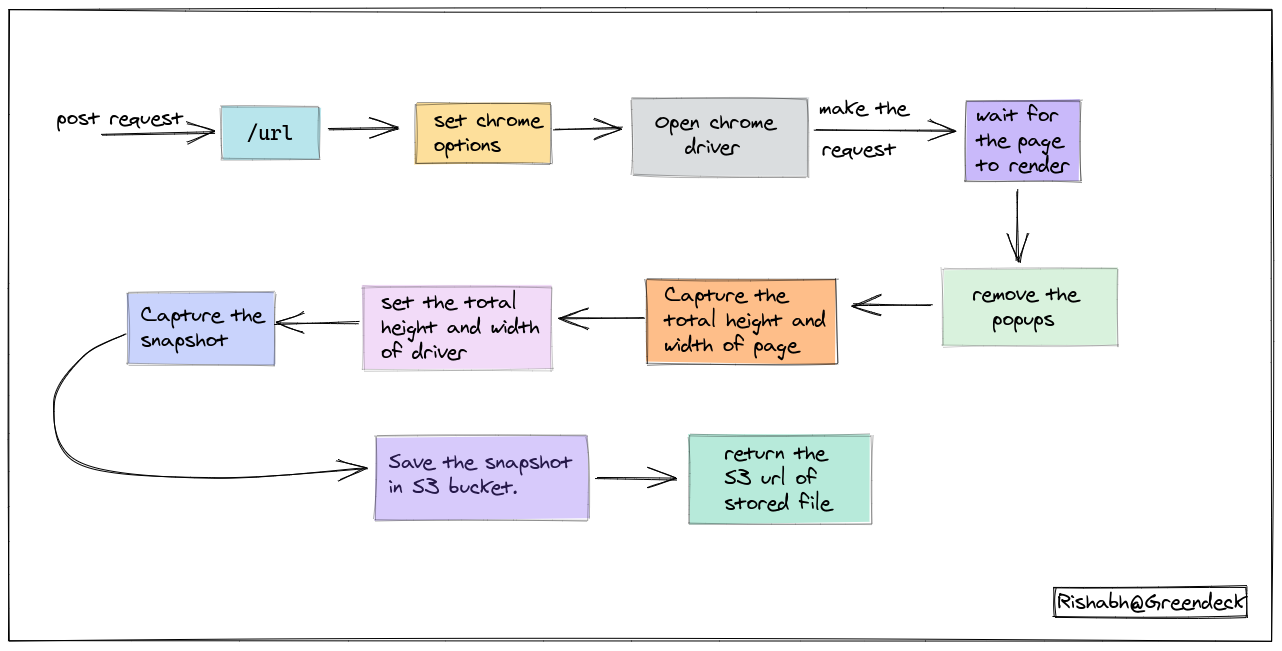
return (total_height, total_width, driver)Working of snapshot service:
- Accept the url/html via a post request on one of the endpoints.
- Set the chrome options before opening the driver, like setting a user agent.
- Open the driver.
- Make a request.
- Wait for the page to get rendered because of single-page applications.
- Remove the popups either by refreshing the page once again or clicking them.
- Scroll from the top-up (0,0) to the bottom to capture the full height and width of the page to be captured.
- Set the width and height of the driver.
- Capture the snapshot.
- Store the captured snapshot in an S3 bucket and then return the url of that stored file.
This service needs to capture the snapshots every day. To accomplish this, we make use of a workflow management tool called Apache airflow. We have done our part by building the service, the scheduling part is being handled by airflow.
The next post will be going to cover how newsletter service works and how it makes use of snapshot service to do the job.
Hope, you will find these insights useful for your use case and let us know if you have any other suggestion for us too!
If you are passionate about this topic, or simply want to say hi, please drop me a line at [email protected].