We at Greendeck provide pricing and retail intelligence solutions to our customers. We help them make great pricing decisions based on data, not intuition.
To accomplish this, one of the major tasks is scraping hundreds of millions of products from many e-commerce stores on a daily basis.
As we’re a data-driven company data forms the basis of Greendeck. If we can’t get the right data, at the right time, things will not move from one place to another.
We need to build a robust and reliable architecture that can complete the scraping operation as quickly as possible, so that other tasks can be executed as well.
Here's a rough overview of what the data pipeline looks like in this case:
- Sending requests and receiving HTML as a response.
- Parsing the response: Extracting the data in the right format.
- Saving the data in the desired schema.
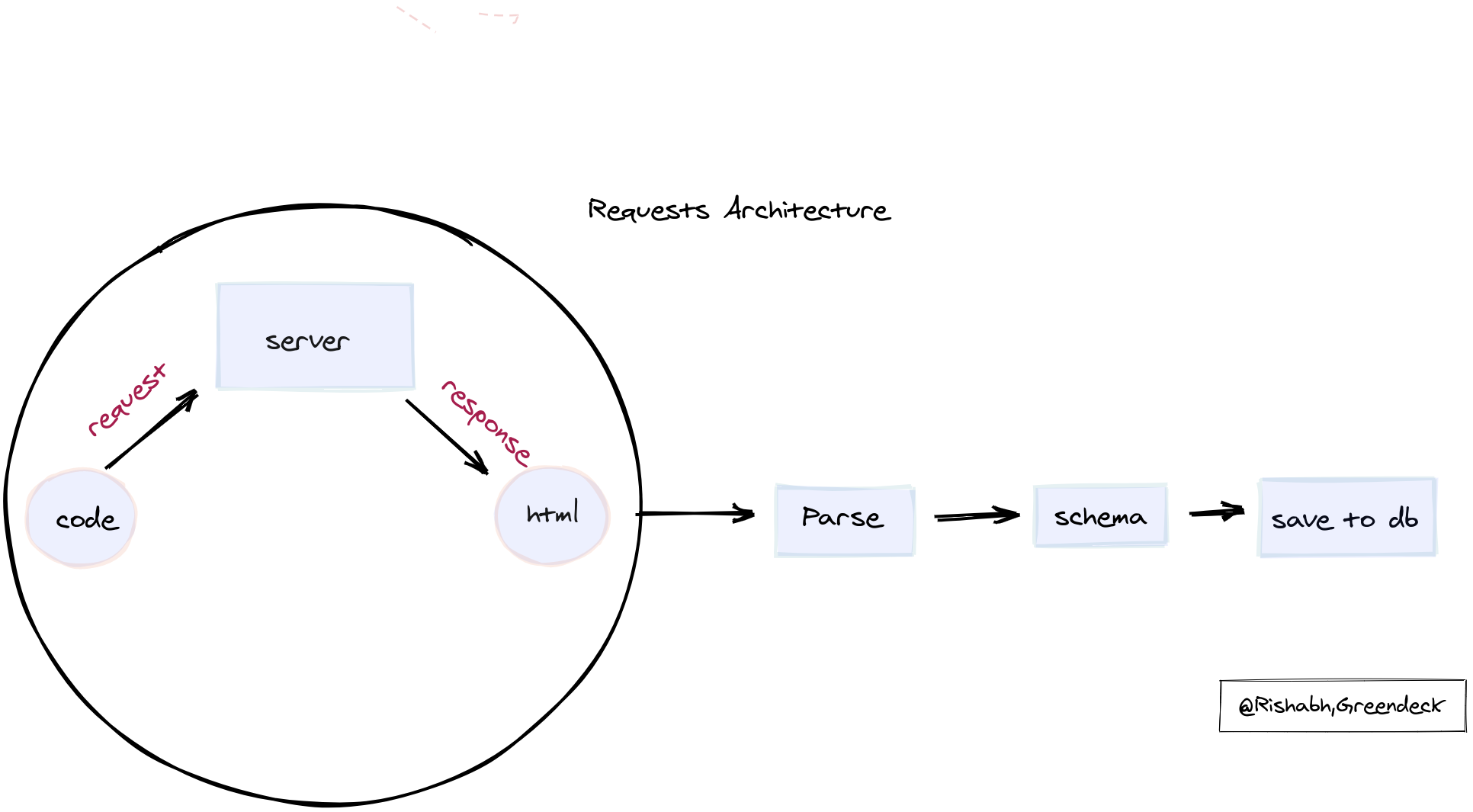
The first task out of these is the most time consuming, and all other tasks depend on it. Getting it right, and making it fast are the basis of this architecture.
Requirements:
- We need to send millions of requests to multiple portals without getting blocked.
- It needs to be fast.
- It needs to be robust and reliable.
- Needs to be cost effective.
This article will be like a journey of each and everything that we tried, the results we got from those experiments, what worked, and what didn’t.
Basic requests
Like most people, we simply started with python’s request module to send requests to the servers. Simple and plain requests just to get started. As per our expectations and requirements, it failed. It failed miserably.
- Super slow.
- We were getting banned by sending so many requests.
- We were just doing
requests.get(url). More on this later.
Simple requests were simply not good enough for us in every aspect.
Before we start thinking about making the process faster, we have to stop getting banned from portals. We start digging into the problem and we find out that we need to act more human than the code that automates the whole process. The portals were blocking us because they were able to know it’s the code behind the scene that’s sending the request, and not the real human. So, we need to mimic the real-world process in code.
That’s where we need to make use of User agents, cookies, and headers.
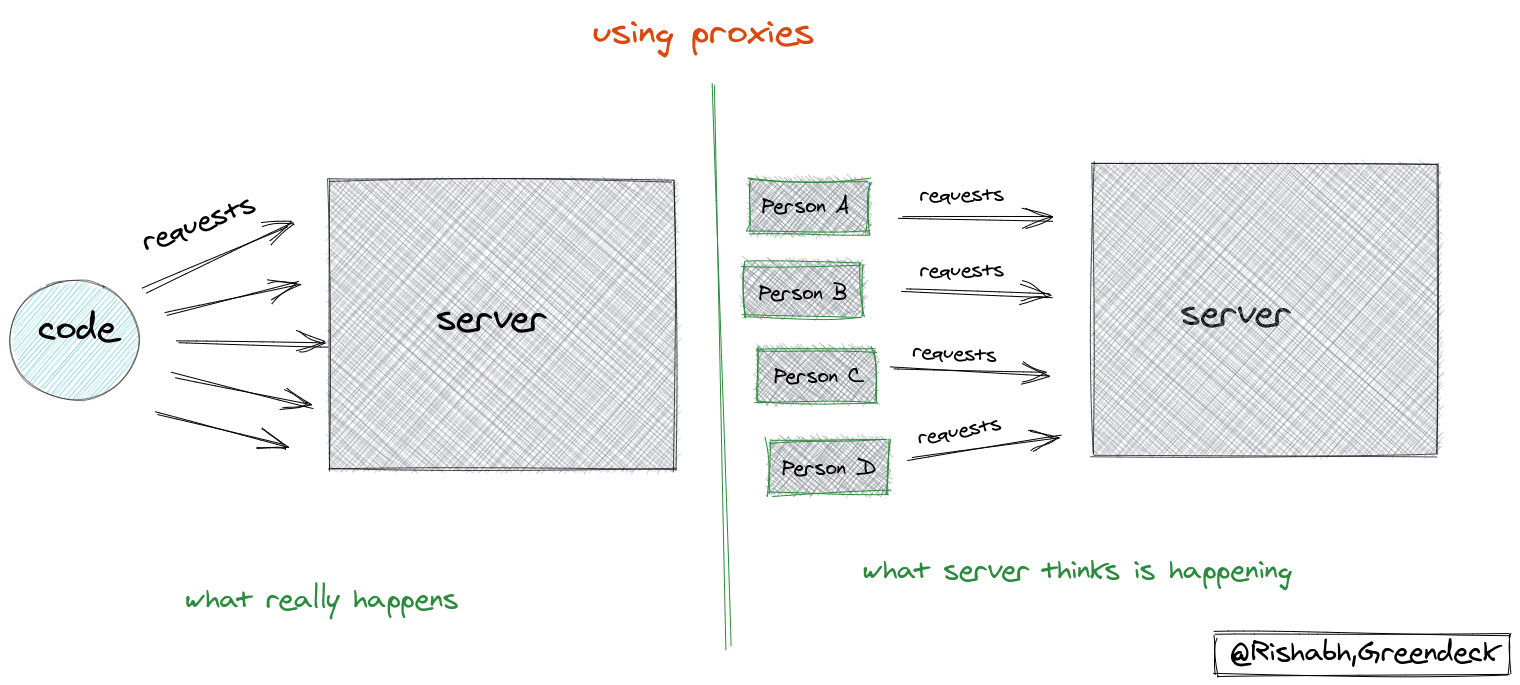
These are like little add-ons that mimic the process of a human being requesting the resource using the browser. Things improved. We start getting a response from some of the portals but the majority of them were still blocking us. The next obvious step is to use proxies. We need to have a very large pool of working proxies at every instance so that we can make use of them to trick the servers that requests are being sent from different locations and by different users. There is a service, at Greendeck that runs 24x7, and that returns working proxies.
Using proxies, user agents, cookies, and headers solved most of the problems for us. Over 95% of the requests that we were making were getting processed without any problem.
How to make it fast?
Before making the process fast, we need to step up the metric that we will be optimising for all of the experiments. It’s easy to get things done when you know what you want to achieve at last.
The metric that we came up with is requests per second. It’s the number of requests completed per second. Dead simple. We need to make this number as high as possible.
The next step is to focus on making it fast. The important thing to realise is that this process is an I/O bound process instead of a computation-based process. So, we can make use of multi-threading and multi-processing without getting restricted by the GIL lock that python interpreter imposes on multi-threaded processes.
We start making use of both multi-threading and multi-processing to send many concurrent requests at the same time. Needless to say, performance increased drastically.
How to stop getting banned again?
After using multi-threading and multi-processing, the speed improved like crazy, but then there comes another problem with it. We start getting blocked again even after using proxies. Now, there comes the choice that we’d to make between two options:
- Using a different proxy for every URL request.
- Using the same proxy for every n requests, where n=number of simultaneous requests allowed by the portal
Going on with option 2 is definitely the right and the only choice because of the limited number of proxies that are available. You can not expect to have millions of proxies available each moment at your disposal. While scraping, you need to be generous and respect the policies of portals. Set this rule in your mind.
So, the total number of requests that we are sending simultaneously to a portal is equal to the total number of proxies that are available multiplied by the number n. The full batch of requests comprises of URLs from different portals. This way we’re respecting the policies and as well as making the best use of our resources.
How to make it faster?
The whole process was still not up to the mark. We know that it can be more optimised. That’s where the idea of using Sessions and DNS caching comes into play.
Sessions
When we just do requests.get(url,headers=headers,proxies=proxies) , it creates the session with the server with each request. That’s like a wasted effort that we were doing. We can leverage the session that we’re creating for the first request, and can use that same session object for further requests. It means that creating a session object using requests.session() for the first time and then using the same session object for each subsequent request. This improved speed tremendously. Sessions turned out to be really useful for our use case.
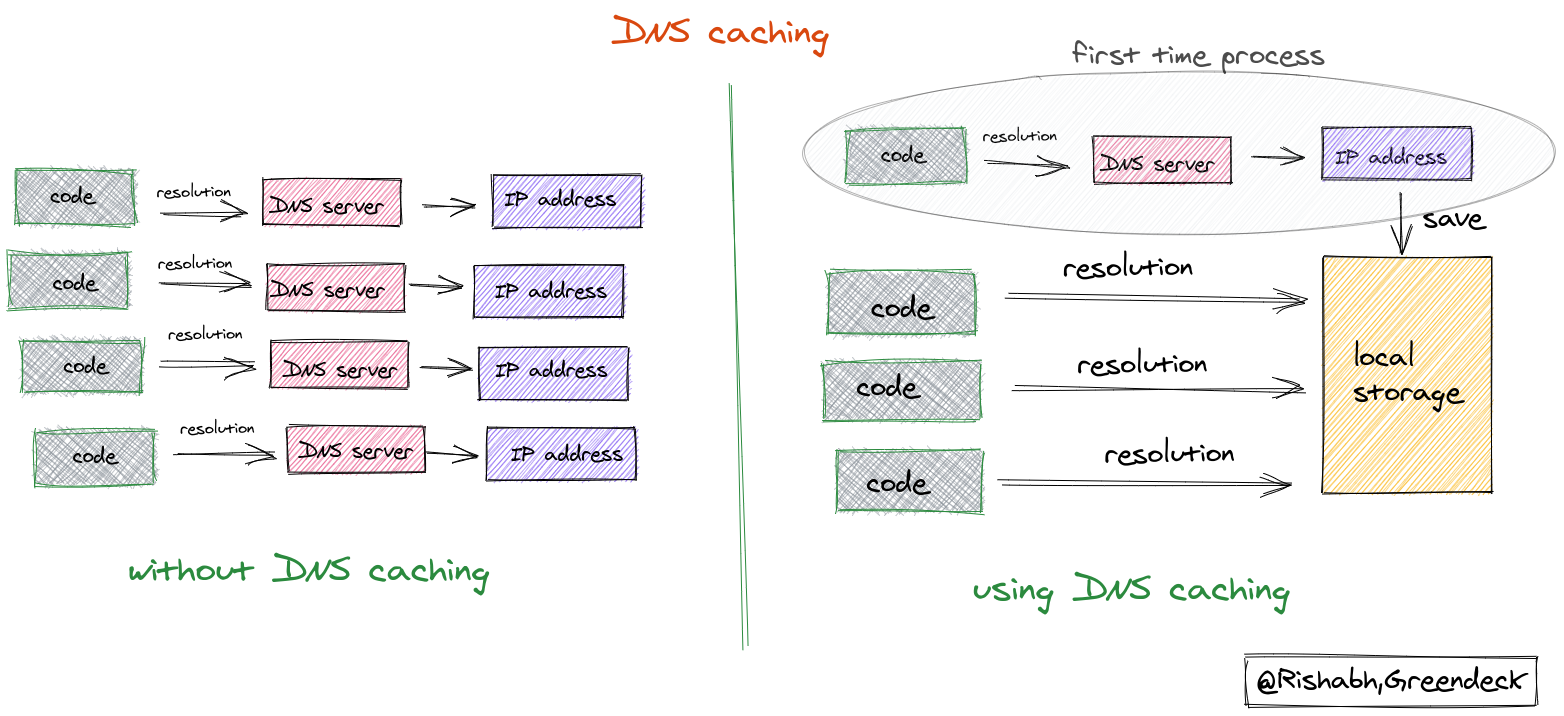
DNS caching
Before, hitting out the actual server, the request first goes through a DNS server that resolves the domain name to the actual IP address of the server. This process takes time to do but it usually gets unnoticed when we send the requests through the browser. We thought, instead of resolving the IP address for the same domain name every time with every request, why not resolve it only once at the start and store the resolved IP address for further requests.
Can we make it even faster?
The same question that was going through our mind, right from the start. Can we make it faster? And the answer came to be, Hell Yes. We start looking out for the good alternatives to python’s request library. After doing a little bit of research, we came to know about pycurl and faster-than-requests.
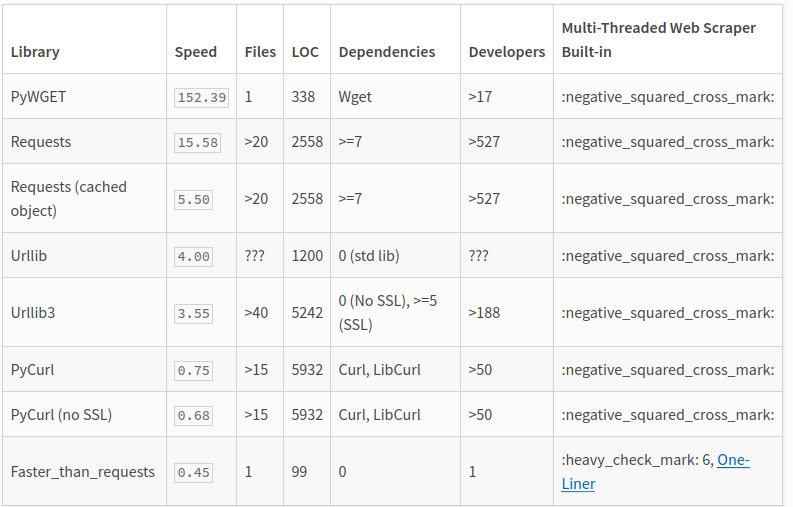
First, we tried faster-than-requests, but came to realise that it doesn’t have the kind of customisation we’re looking for. There are very few parameters that the developer can pass while making requests. Approximately, 95% of our requests are done using user agents, cookies, proxies, and headers. So, we dropped out the idea of using faster-than-requests.
Then, we tried out pycurl, that’s mainly a python wrapper over the libcurl library. It worked out really great. We noticed the speed improvement by 3x.
These were all of the experiments that we’d done so far to make our architecture more fast and reliable. The process is still not complete. We have just barely scratched the surface of what’s possible. There are lots of things that can be tried and in return it can be more optimised.
Hope, you will find these insights useful for your use case and let us know if you have any other suggestion for us too!
If you are passionate about this topic, or simply want to say hi, please drop me a line at [email protected].